Story Points Considered Harmful - Or why the future of estimation is really in our past...
This article is the companion to a talk that myself and @josephpelrine gave at OOP 2012.

We have a lot to learn from our ancestors. One that I want to focus on for this post is Galileo.
Galileo was what we would call today a techie. He loved all things tech and was presented an interesting technology that he could not put down. Through that work he developed optic technology to build first a telescope and later a microscope.
Through the use of the telescope and other approaches he came to realize and defend the Heliocentric view of the universe: the Earth was not the center of the Universe, but rather moved around the Sun.
This discovery caused no controversy until Galileo wrote it down and apparently discredited the view held by the Church at that time. The Church believed and defended that the Universe was neatly organized around the Earth and everything moved around our lanet.
We now know that Galileo was right and that the Church was - as it often tends to be with uncritical beliefs - wrong. We now say obviously the Earth is round and moves around the Sun. Or do we...
The fact that is that even today many people hold uncritical beliefs about how our world really works. Or our projects in the case of this post...
What do all of these techniques have in common? They all look towards the future!
Why is this characteristic important?
Take the example of a goal-keeper in a football (aka soccer) match. She can easily predict how a simple kick will propel the ball towards the goal, and she can do that with quite a high accuracy (as proven by the typically low scores in today's football games). But even in soccer, if you face a player like Maradona, or Beckham, or Crisitiano Ronaldo it is very difficult to predict the trajectory of the ball. Some physicists have spent considerable amount of time analyzing the trajectory of Beckham's amazing free kicks to try to understand how the ball moves and why. Obviously a goal-keeper does not have the computers or the time to analyze the trajectory of Beckham's free kicks therefore Beckham ends up scoring quite a few goals that way. Even in football, where well-known physics laws always apply it is some times hard to predict the immediate future!
The undisputed fact is that we, humans are very bad at predicting the future.
But that is not all!
Lately, and especially in the agile field we have been finding a new field of study: Complexity Sciences.
A field of study that tries to identify rules that help us navigate a world where even causality (cause and effect) are challenged.
An example may be what you may have heard of, the Butterfly effect: "where a small change at one place in a nonlinear system can result in large differences to a later state".
Complexity Sciences are helping us develop our own understanding of software development based on the theories developed in the last few years.
Scrum being a perfect example of a method that has used Complexity to inspire and justify its approach to many of the common problems we face in Software development.
Scrum has used "self-organization", and "emergence" as concepts in explaining why the Scrum approach works. Here's the problem: there's a catch.
In a complex environment we don’t have discernible causality!
Sometimes this is due to delayed effects from our actions, most often it is so that we attribute causality to events in the past when in fact no cause-effect relationship exists (Retrospective Coherence). But, in the field of estimation this manifests itself in a different way.
In order for us to be able to estimate we need to assume that causality exists (if I ask Tom for the code review, then Helen will be happy with my pro-activeness and give me a bonus. Or will she?) The fact is: in a Complex environment, this basic assumption of the existence of discernible Causality is not valid! Without causality, the very basic assumption that justifies estimation falls flat!
So, which is it? Do we have a complex environment in software development or not? If we do then we cannot - at the same time - argue for estimation (and build a whole religion on it)! In contrast, if we are not in a complex environment we cannot then claim that Scrum - with it’s focus on solving a problem in the complex domain - can work!
So then, the question for us is: Can this Story Point based estimation be so important to the point of being promoted and publicized in all Scrum literature?
Luckily we have a simple alternative that allows for the existence of a complex environment and solves the same problems that Story Points were designed (but failed to) solve.
Can it really be that simple? To test this approach I looked at data from different projects and tried to answer a few simple questions
And here's what I found:
Although there's no explanation about what "change our mind" means in the book, one can infer that the goal is not to have to spend too much time trying to be right. The reason for this is, of course, that if a story changes the size slightly there's no impact on the Story Point estimate, but what if the story changes size drastically?
Well, at this time you would probably have another estimation session, or you would break down that story into some smaller granularity stories to have a better picture of it's actual size and impact on the project.
On the other hand, if we were to use a simple metric like the number of stories completed we would be able to immediately assess the impact of the new items in the progress for the project.
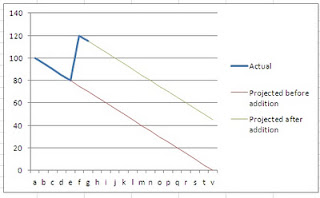 As illustrated in the graph, if we have a certain number of stories to complete (80 in our example) and suddenly some 40 are added to our backlog (breaking down an Epic for example) we can easily see the impact of that in our project progress.
As illustrated in the graph, if we have a certain number of stories to complete (80 in our example) and suddenly some 40 are added to our backlog (breaking down an Epic for example) we can easily see the impact of that in our project progress.
In this case, as we can see from the graph, the impact of a story changing it's meaning or a large story being broken down into smaller stories has an impact on the project and we can see that immediate impact directly in the progress graph.
This leads me to conclude that regarding Claim 1, Story Points offer no advantage over just simply counting the number of items left to be Done.
Allowing for large estimates for items in the backlog (say a 100SP Epic) does help to account in some way for the uncertainty that large pieces of work represent.
However, the same uncertainty exists in any way we may use to measure progress. The fact is that we don’t really know if an Epic (say 100 SPs) is really equivalent to a similar size aggregate of User Stories (say 100 times 1 SP story). Conclusion: there is no significant added information by classifying a story in a 100 SP category which in turn means that calling something an "Epic" is about the same information as classifying it as a 100 Story Points Epic.
Basing your progress assessment on the Number of Items completed in each Sprint is faster to calculate (number of items in the PBL / velocity in number of items Done per Sprint = number of Sprints left) and can be used to provide critical information about project progress. Here's a real-life example:
This meant that significant effort was made to come up with a coherent Product Backlog. The Backlog was reviewed by Sales and Pre-Sales (technical sales) people. All agreed, we really needed to deliver around 140 Stories (not points, Stories) to be able to compete.
As we were not the first in the market we had a tight market window. Failing to meet that window would invalidate the need to enter that market at all.
So, we started the project and in the first Sprint we complete 1 single Story (maybe it was a big story -- truth is I don't remember). Worst, in the same period another 20 stories were added to the Product Backlog. As expected, the Product Management and Sales discovered a few more stories that were really a "must" and could not be left out of the product.
The team was gaining speed and in the second Sprint they got 8 stories to "Done". They were happy. At the same time the Product Manager and the Sales agreed to a cut-down version of the Product Backlog and removed some 20 stories from the Backlog.
After the third sprint the team had achieved velocities of 1 (first Sprint), 8 (second) and 8 (third). The fourth sprint was about to start and the pressure was high on the team and on the Product Manager. During the Sprint planning meeting the team committed to 15 new stories. This was a good number, as a velocity of 15 would make the stakeholders believe that the project could actually deliver the needed product. They would need to keep a velocity of 15 stories per sprint for 11 months. Could they make it?
I ask this question from the audience every time I tell this story. I get many different answers. Every audience comes up with 42 as a possible answer (to be expected given the crowds I talk to), but most say 8, 10, some may say 15 (very few), some say 2 (very few). The consensus seems to be around 8-10.
At this point I ask the audience why they would say 8-10 instead of 15 as the Product Manager for that team said. Obviously the Product Manager knew the team and the context better, right?
At the end of the fourth sprint the team completed 10 items, which even if it was 20% more than what they had done in previous sprints was still very far from the velocity they needed to make the project a success. The management reflected on the situation and clearly decided that the best decision for the company was to cancel that product.
We avoided a death-march project and were able to focus on other more important products for the company's future. Products that now bring in significant amount of money!
Don't estimate the size of a story further than this: when doing Backlog Grooming or Sprint Planning just ask: can this Story be completed in a Sprint by one person? If not, break the story down!
For large projects use a further level of abstraction: Stories fit into Sprints, therefore Epics fit into meta-Sprints (for example: meta-Sprint = 4 Sprints). Ask the same question of Epics that you do of Sprints (can one team implement this Epic in half a meta-Sprint, i.e. 2 Sprints?) and break them down if needed.
By continuously harmonizing the size of the Stories/Epics you are creating a distribution of the sizes around the median:
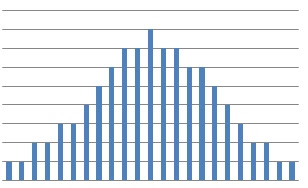
Assuming a normal distribution of the size of the stories means that you can assume that for the purposes of looking at the long term (remember: this only applies on the long term, i.e. more than 3 sprints into the future) estimation/progress of the project, you can assume that all stories are the same size, and can therefore measure progress by measuring the number of items completed per Sprint.
My aim with this post is to demystify the estimation in Agile projects. The fact is: the data we have available (see above) does not allow us to accept any of the claims by Mike Cohn regarding the use of Story Points as a valid/useful estimation technique, therefore you are better off using a much simpler technique! Let me know if you find an even simpler one!
Oh, and by the way: stop wasting time trying to estimate a never ending Backlog. There's no evidence that that will help you predict the future any better than just counting the number of stories "Done"!

Photo credit: write_adam @ flickr

We have a lot to learn from our ancestors. One that I want to focus on for this post is Galileo.
Galileo was what we would call today a techie. He loved all things tech and was presented an interesting technology that he could not put down. Through that work he developed optic technology to build first a telescope and later a microscope.
Through the use of the telescope and other approaches he came to realize and defend the Heliocentric view of the universe: the Earth was not the center of the Universe, but rather moved around the Sun.
This discovery caused no controversy until Galileo wrote it down and apparently discredited the view held by the Church at that time. The Church believed and defended that the Universe was neatly organized around the Earth and everything moved around our lanet.
We now know that Galileo was right and that the Church was - as it often tends to be with uncritical beliefs - wrong. We now say obviously the Earth is round and moves around the Sun. Or do we...
The Flat Earth Society
Actually, there are still many people around (curious word, isn't it?) the planet that do not even believe that the Earth is round! Don't believe me? Then check The Flat Earth Society.The fact that is that even today many people hold uncritical beliefs about how our world really works. Or our projects in the case of this post...
Estimation soup
We've all been exposed to various estimation techniques, in an Agile or traditional project. Here are some that quickly come to mind: Expert Estimation, Consensus Estimation, Function Point Analysis, etc. Then we have cost (as opposed to only time) estimation techniques: COCOMO, SDM, etc. And of course, the topic of this post: Story Point Estimation.What do all of these techniques have in common? They all look towards the future!
Why is this characteristic important?
The Human condition
This characteristic is nt because looking at the future is always difficult! We humans are very good at anticipating immediate events in the physical world, but in the software world what we estimate is neither immediate, nor does it follow any physical laws that we intuitively understand!Take the example of a goal-keeper in a football (aka soccer) match. She can easily predict how a simple kick will propel the ball towards the goal, and she can do that with quite a high accuracy (as proven by the typically low scores in today's football games). But even in soccer, if you face a player like Maradona, or Beckham, or Crisitiano Ronaldo it is very difficult to predict the trajectory of the ball. Some physicists have spent considerable amount of time analyzing the trajectory of Beckham's amazing free kicks to try to understand how the ball moves and why. Obviously a goal-keeper does not have the computers or the time to analyze the trajectory of Beckham's free kicks therefore Beckham ends up scoring quite a few goals that way. Even in football, where well-known physics laws always apply it is some times hard to predict the immediate future!
The undisputed fact is that we, humans are very bad at predicting the future.
But that is not all!
This is when things get Complex
Lately, and especially in the agile field we have been finding a new field of study: Complexity Sciences.
A field of study that tries to identify rules that help us navigate a world where even causality (cause and effect) are challenged.
An example may be what you may have heard of, the Butterfly effect: "where a small change at one place in a nonlinear system can result in large differences to a later state".
Complexity Sciences are helping us develop our own understanding of software development based on the theories developed in the last few years.
Scrum being a perfect example of a method that has used Complexity to inspire and justify its approach to many of the common problems we face in Software development.
Scrum has used "self-organization", and "emergence" as concepts in explaining why the Scrum approach works. Here's the problem: there's a catch.
Why did this just happen?
In a complex environment we don’t have discernible causality!
Sometimes this is due to delayed effects from our actions, most often it is so that we attribute causality to events in the past when in fact no cause-effect relationship exists (Retrospective Coherence). But, in the field of estimation this manifests itself in a different way.
In order for us to be able to estimate we need to assume that causality exists (if I ask Tom for the code review, then Helen will be happy with my pro-activeness and give me a bonus. Or will she?) The fact is: in a Complex environment, this basic assumption of the existence of discernible Causality is not valid! Without causality, the very basic assumption that justifies estimation falls flat!
Solving the the lack of internal coherence in Scrum
So, which is it? Do we have a complex environment in software development or not? If we do then we cannot - at the same time - argue for estimation (and build a whole religion on it)! In contrast, if we are not in a complex environment we cannot then claim that Scrum - with it’s focus on solving a problem in the complex domain - can work!
So then, the question for us is: Can this Story Point based estimation be so important to the point of being promoted and publicized in all Scrum literature?
Luckily we have a simple alternative that allows for the existence of a complex environment and solves the same problems that Story Points were designed (but failed to) solve.
The alternative prediction device
The alternative to Story Point estimation is simple: just count the number of Stories you have completed (as in "Done") in the previous iterations. They are the best indicator of future performance! Then use that information to project future progress. Basically, the best predictor of the future is your past performance!Can it really be that simple? To test this approach I looked at data from different projects and tried to answer a few simple questions
The Experiment
- Q1: Is there sufficient difference between what Story Points and ’number of items’ measure to say that they don’t measure the same thing?
- Q2: Which one of the two metrics is more stable? And what does that mean?
- Q3: Are both metrics close enough so that measuring one (number of items) is equivalent to measuring the other (Story Points)?
And here's what I found:
- Regarding Question 1: I noticed that there was a stable medium-to-high correlation between the Story Point estimation and the simple count of Stories completed (0,755; 0,83; 0,92; 0,51(!); 0,88; 0,86; 0,70; 0,75; 0,88). With such a high correlation it is likely that both metrics represent a signal of the same underlying information.
- Regarding Question 2: The normalized data (normalized for Sprint/Iteration length) has similar value of Standard Deviation(equally stable). Leading me to conclude that there is no significant difference in stability of either of the metrics. Although in absolute terms the Story Point estimations vary much more between iterations than the number of completed/Done Stories
- Regarding Question 3: Both metrics (Story Points completed vs Number of Stories completed) seem to measure the same thing. So...
- Claim 1: The use of Story points allows us to change our mind whenever we have new information about a story
- Claim 2: The use of Story points works for both epics and smaller stories
- Claim 3: The use of Story points doesn’t take a lot of time
- Claim 4: The use of Story points provides useful information about our progress and the work remaining
- Claim 5: The use of Story points is tolerant of imprecision in the estimates
- Claim 6: The use of Story points can be used to plan releases
Claim 1: The use of Story points allows us to change our mind whenever we have new information about a story
Although there's no explanation about what "change our mind" means in the book, one can infer that the goal is not to have to spend too much time trying to be right. The reason for this is, of course, that if a story changes the size slightly there's no impact on the Story Point estimate, but what if the story changes size drastically?
Well, at this time you would probably have another estimation session, or you would break down that story into some smaller granularity stories to have a better picture of it's actual size and impact on the project.
On the other hand, if we were to use a simple metric like the number of stories completed we would be able to immediately assess the impact of the new items in the progress for the project.
 As illustrated in the graph, if we have a certain number of stories to complete (80 in our example) and suddenly some 40 are added to our backlog (breaking down an Epic for example) we can easily see the impact of that in our project progress.
As illustrated in the graph, if we have a certain number of stories to complete (80 in our example) and suddenly some 40 are added to our backlog (breaking down an Epic for example) we can easily see the impact of that in our project progress.In this case, as we can see from the graph, the impact of a story changing it's meaning or a large story being broken down into smaller stories has an impact on the project and we can see that immediate impact directly in the progress graph.
This leads me to conclude that regarding Claim 1, Story Points offer no advantage over just simply counting the number of items left to be Done.
Claim 2: The use of Story points works for both epics and smaller stories
Allowing for large estimates for items in the backlog (say a 100SP Epic) does help to account in some way for the uncertainty that large pieces of work represent.
However, the same uncertainty exists in any way we may use to measure progress. The fact is that we don’t really know if an Epic (say 100 SPs) is really equivalent to a similar size aggregate of User Stories (say 100 times 1 SP story). Conclusion: there is no significant added information by classifying a story in a 100 SP category which in turn means that calling something an "Epic" is about the same information as classifying it as a 100 Story Points Epic.
Claim 3: The use of Story points doesn’t take a lot of time
Having worked with Story Points for several years this is not my experience. Although some progress has been done by people like Ken Power (at Cisco) with the Silent Grouping technique, the fact that we need such technique should dispute any idea that estimating in SP’s "doesn’t take a lot of time". In fact, as anybody that has tried a non-trivial project knows it can take days of work to estimate the initial backlog for a reasonable size project.Claim 5: The use of Story points is tolerant of imprecision in the estimates
Although you can argue that this claim holds - even if the book does not explain how - there's no data to justify the belief that Story Points do this better than merely counting the number of Stories Done. In fact, we can argue that counting the number of stories is even more tolerant of imprecisions (see below for more details on this)Claim 6: Story points can be used to plan releases
Fair enough. On the other hand we can use any estimation technique to do this, so how would Story Points be better in this particular claim than any other estimation technique? Also, as we will see when analysis Claim 4, counting the number of Stories Done (and left to be Done) is a very effective way to plan a release (be patient, the example is coming up).Claim 4: The use of Story points provides useful information about our progress and the work remaining
This claim holds true if, and only if you have estimated all of your stories in the Backlog and go through the same process for each new story added to the Backlog. Even the stories that will only be developed a few months or even a year later (for long projects) must be estimated! This approach is not very efficient (which in fact contradicts Claim 3).Basing your progress assessment on the Number of Items completed in each Sprint is faster to calculate (number of items in the PBL / velocity in number of items Done per Sprint = number of Sprints left) and can be used to provide critical information about project progress. Here's a real-life example:
The real-life use of a simpler metric for project progress measurement
In a company I used to work at we had a new product coming to market. It was not a "first-mover" which meant that the barrier to entry was quite high (at least that was the belief from Product Management and Sales).This meant that significant effort was made to come up with a coherent Product Backlog. The Backlog was reviewed by Sales and Pre-Sales (technical sales) people. All agreed, we really needed to deliver around 140 Stories (not points, Stories) to be able to compete.
As we were not the first in the market we had a tight market window. Failing to meet that window would invalidate the need to enter that market at all.
So, we started the project and in the first Sprint we complete 1 single Story (maybe it was a big story -- truth is I don't remember). Worst, in the same period another 20 stories were added to the Product Backlog. As expected, the Product Management and Sales discovered a few more stories that were really a "must" and could not be left out of the product.
The team was gaining speed and in the second Sprint they got 8 stories to "Done". They were happy. At the same time the Product Manager and the Sales agreed to a cut-down version of the Product Backlog and removed some 20 stories from the Backlog.
After the third sprint the team had achieved velocities of 1 (first Sprint), 8 (second) and 8 (third). The fourth sprint was about to start and the pressure was high on the team and on the Product Manager. During the Sprint planning meeting the team committed to 15 new stories. This was a good number, as a velocity of 15 would make the stakeholders believe that the project could actually deliver the needed product. They would need to keep a velocity of 15 stories per sprint for 11 months. Could they make it?
The climax
As the fourth sprint started I made a bet with the Product Manager. I asked him how many items he believed that the team could complete and he said 15 (just as the team had committed to). I disagreed and said 10. How many items would you have said the team could complete?I ask this question from the audience every time I tell this story. I get many different answers. Every audience comes up with 42 as a possible answer (to be expected given the crowds I talk to), but most say 8, 10, some may say 15 (very few), some say 2 (very few). The consensus seems to be around 8-10.
At this point I ask the audience why they would say 8-10 instead of 15 as the Product Manager for that team said. Obviously the Product Manager knew the team and the context better, right?
At the end of the fourth sprint the team completed 10 items, which even if it was 20% more than what they had done in previous sprints was still very far from the velocity they needed to make the project a success. The management reflected on the situation and clearly decided that the best decision for the company was to cancel that product.
Story Points Myth: Busted!
That company did that extremely hard decision based on data, not speculation from Project Managers, not based on some bogus estimation using whatever technique. Real data. They looked at the data available to them and decided to cancel the project 10 months before its originally planned release. This project had a team of about 20 people. Canceling the project saved the company 200 man-month of investment in a product they had no hope of getting out of the door!We avoided a death-march project and were able to focus on other more important products for the company's future. Products that now bring in significant amount of money!
OK, I get your point, but how does that technique work?
Most people will be skeptical at this point (if you've read this far you probably are too). So let me explain how this works out.Don't estimate the size of a story further than this: when doing Backlog Grooming or Sprint Planning just ask: can this Story be completed in a Sprint by one person? If not, break the story down!
For large projects use a further level of abstraction: Stories fit into Sprints, therefore Epics fit into meta-Sprints (for example: meta-Sprint = 4 Sprints). Ask the same question of Epics that you do of Sprints (can one team implement this Epic in half a meta-Sprint, i.e. 2 Sprints?) and break them down if needed.
By continuously harmonizing the size of the Stories/Epics you are creating a distribution of the sizes around the median:

Assuming a normal distribution of the size of the stories means that you can assume that for the purposes of looking at the long term (remember: this only applies on the long term, i.e. more than 3 sprints into the future) estimation/progress of the project, you can assume that all stories are the same size, and can therefore measure progress by measuring the number of items completed per Sprint.
Final words
As with all techniques this one comes with a disclaimer: you may not see the same effects that I report in this post. That's fine. If that is the case please share the data you have with me and I'm happy to look at it.My aim with this post is to demystify the estimation in Agile projects. The fact is: the data we have available (see above) does not allow us to accept any of the claims by Mike Cohn regarding the use of Story Points as a valid/useful estimation technique, therefore you are better off using a much simpler technique! Let me know if you find an even simpler one!
Oh, and by the way: stop wasting time trying to estimate a never ending Backlog. There's no evidence that that will help you predict the future any better than just counting the number of stories "Done"!
How do I apply #NoEstimates to improve estimation? Here's how...
Photo credit: write_adam @ flickr
Labels: agile, agile estimation, estimation, kanban, lean, planning, planning poker, pmot, project management, project planning, release planning
RSS link



